Abstract
Recent advances in Vision-Language Models (VLMs) have improved performance in multi-modal learning, raising the question of whether these models truly understand the content they process. Crucially, can VLMs detect when a reasoning process is wrong and identify its error type? To answer this, we present MMErroR, a multi-modal benchmark of 1997 samples, each embedding a single coherent reasoning error. These samples span 24 subdomains across six top-level domains, ensuring broad coverage and taxonomic richness. Unlike existing benchmarks that focus on answer correctness, MMErroR targets a process-level, error-centric evaluation that requires models to detect incorrect reasoning and classify the error type within both visual and linguistic contexts. We evaluate 12 representative VLMs, and even the best model, Gemini-3-Pro-Preview, classifies the error correctly in only 66.65% of cases, underscoring the challenge of identifying erroneous reasoning. Furthermore, the ability to accurately identify errors offers valuable insights into the capabilities of multi-modal models.
Overview
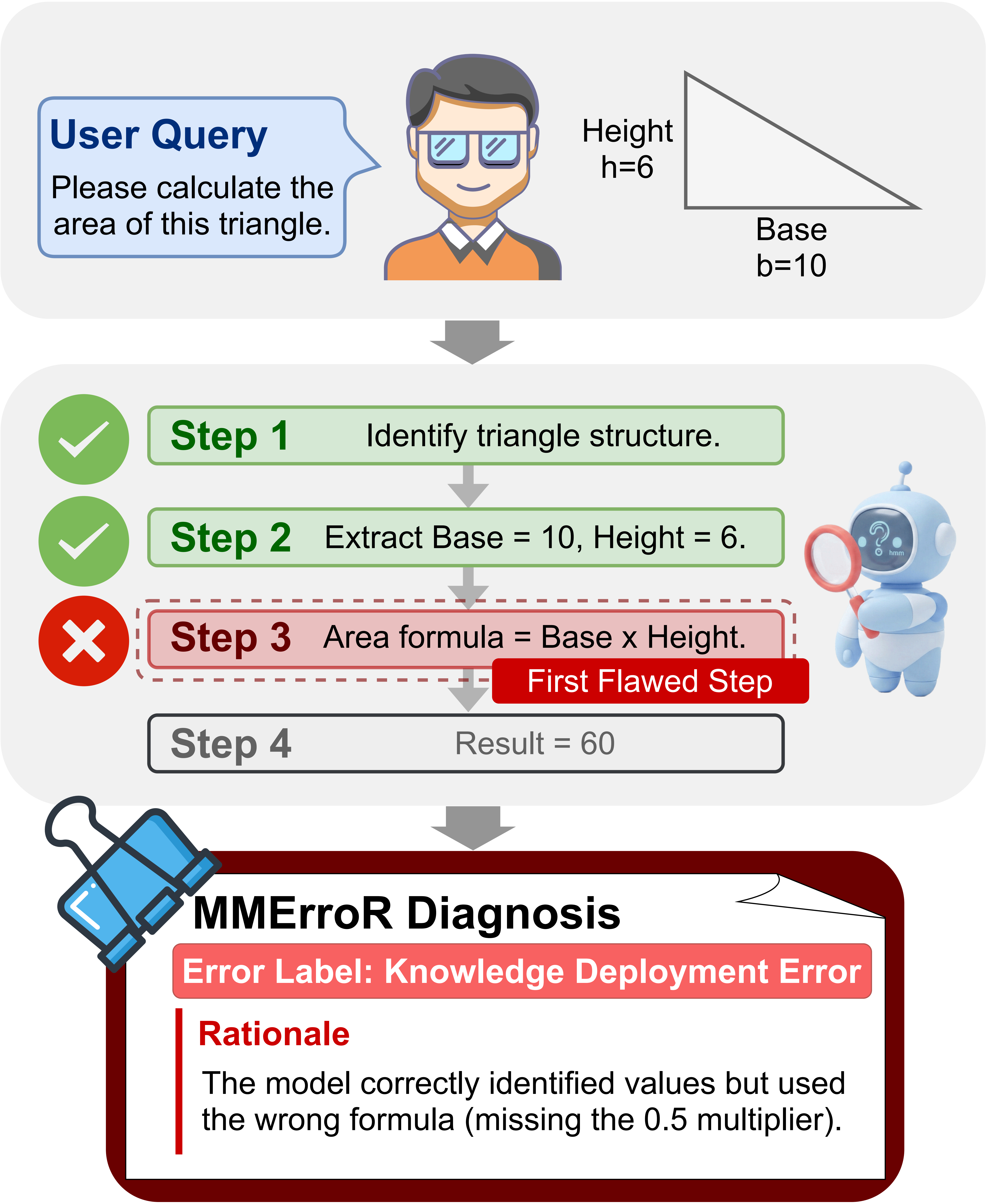
MMErroR evaluates whether a vision-language model can move beyond answer correctness and identify why a reasoning chain fails.
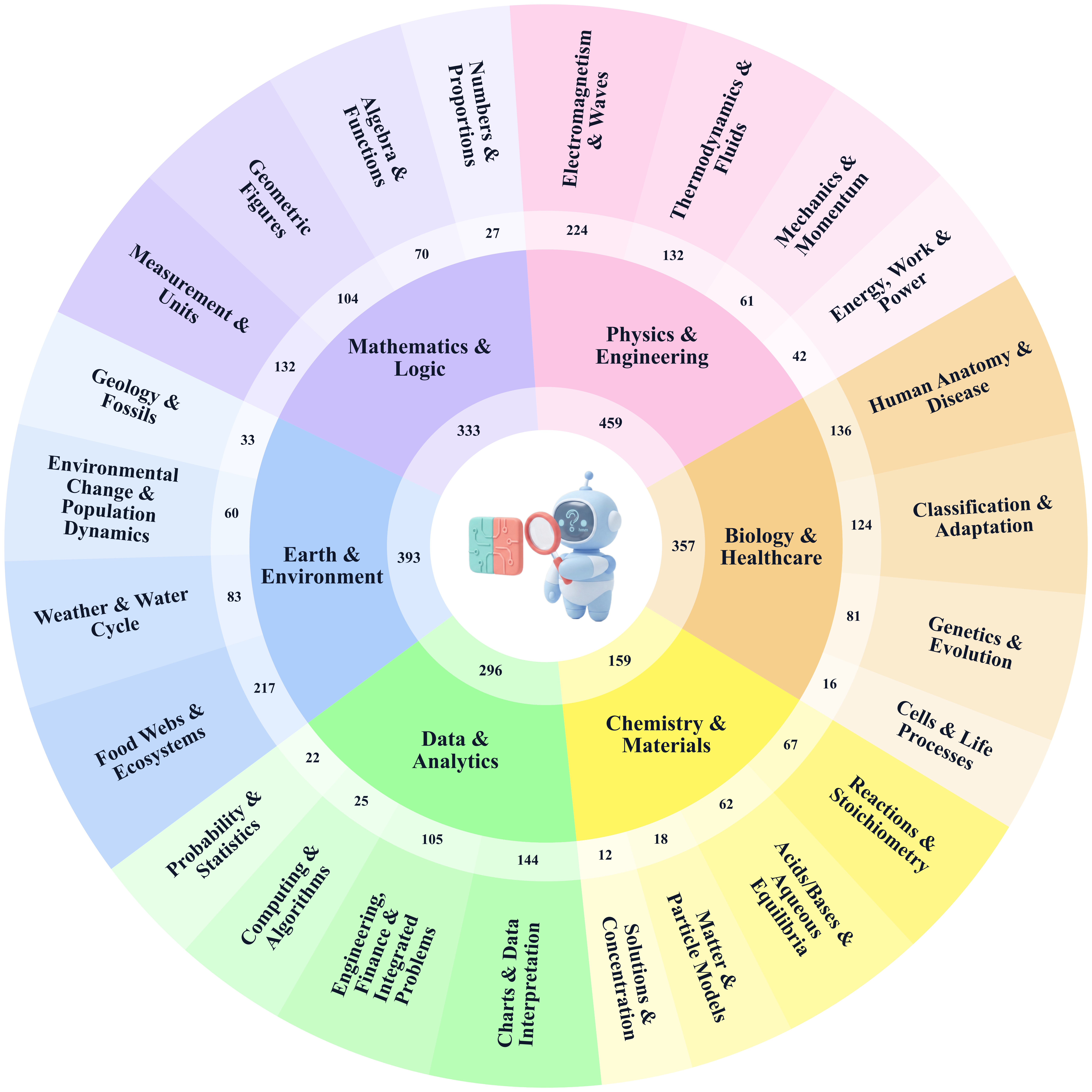
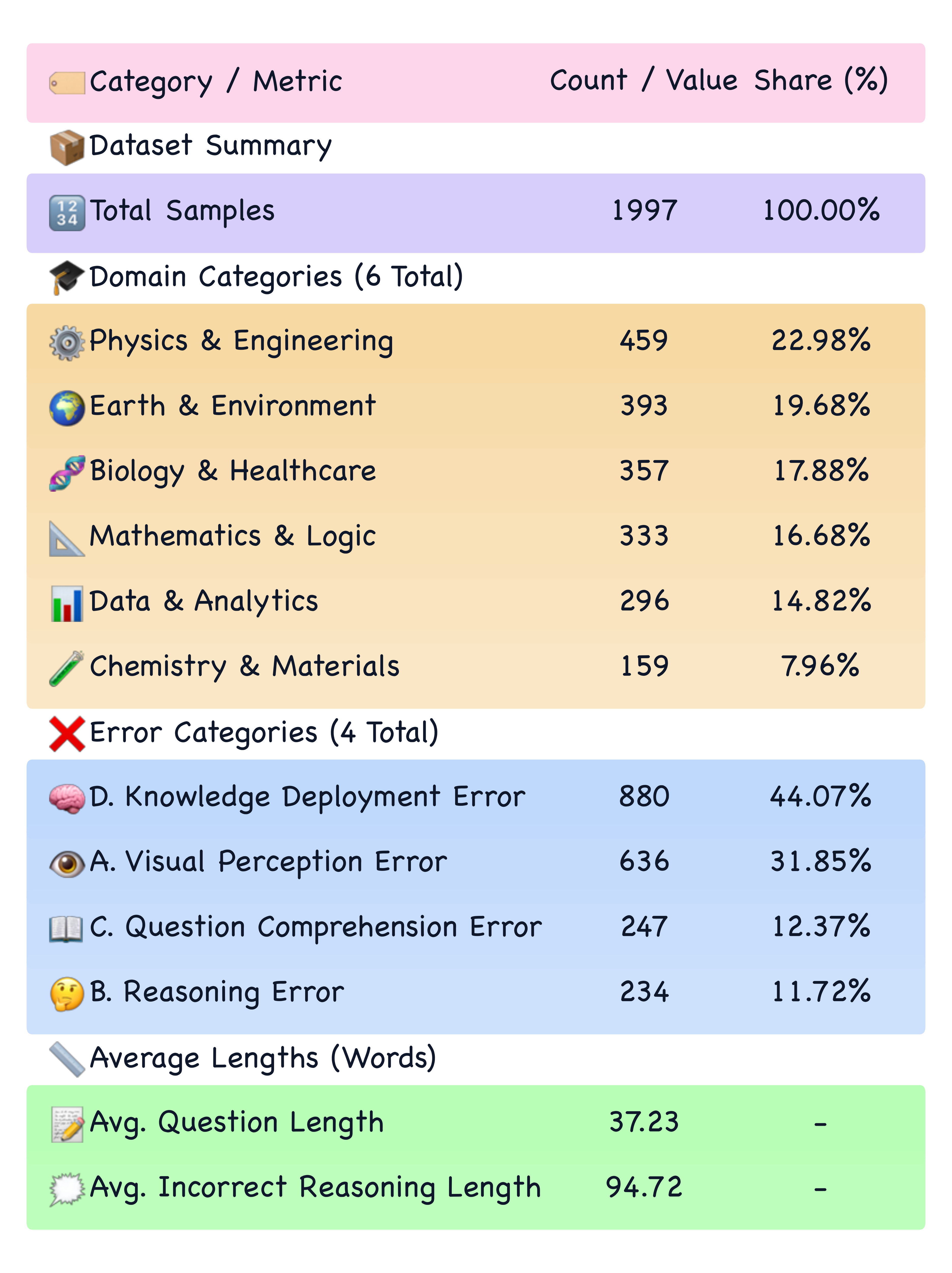
Statistics
MMErroR contains 1,997 multimodal samples across six domains and 24 subdomains. Each sample contains exactly one verified root-cause error.
Experiment Results
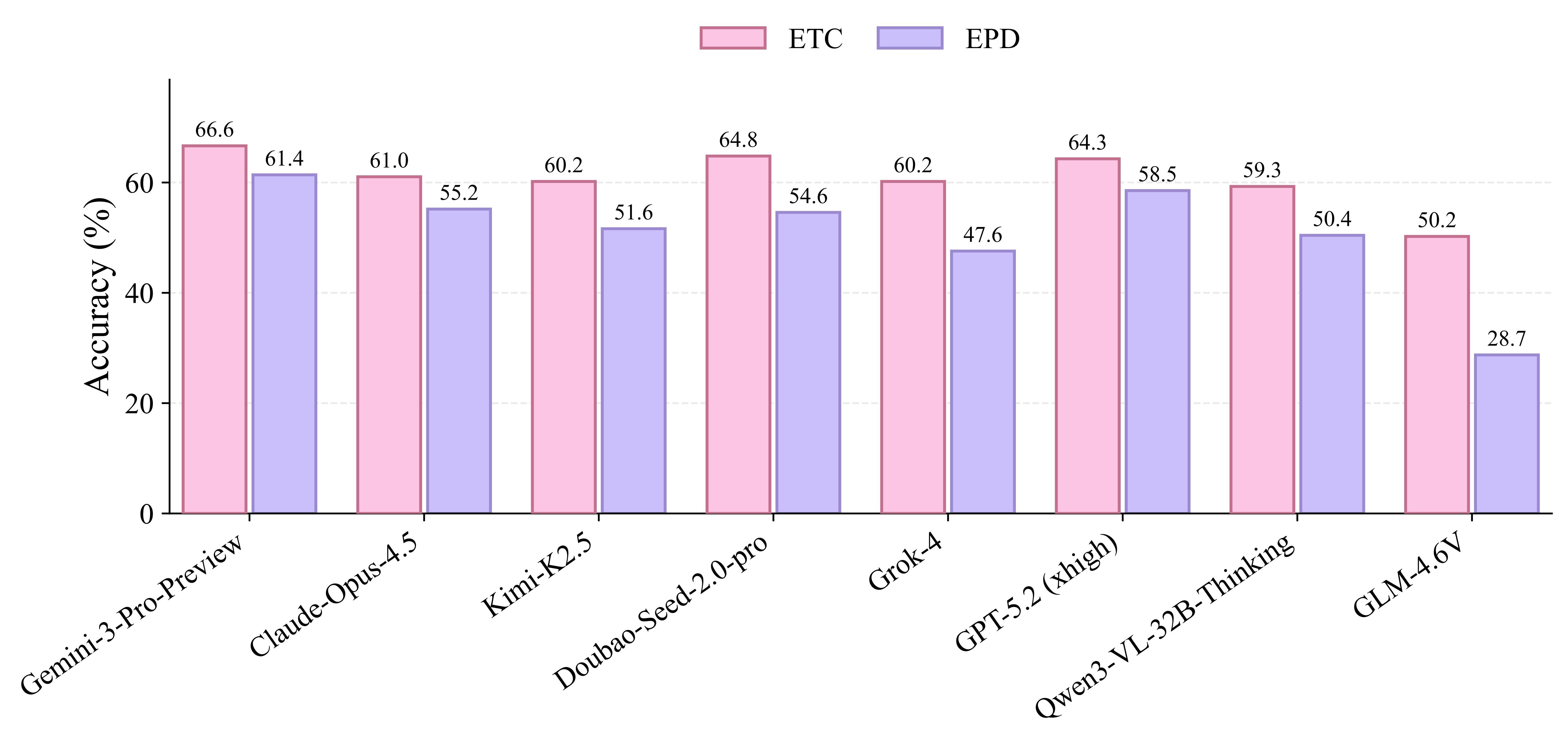
Representative VLMs are evaluated under Error Type Classification (ETC) and Error Presence Detection (EPD), exposing broad gaps in process-level error diagnosis.
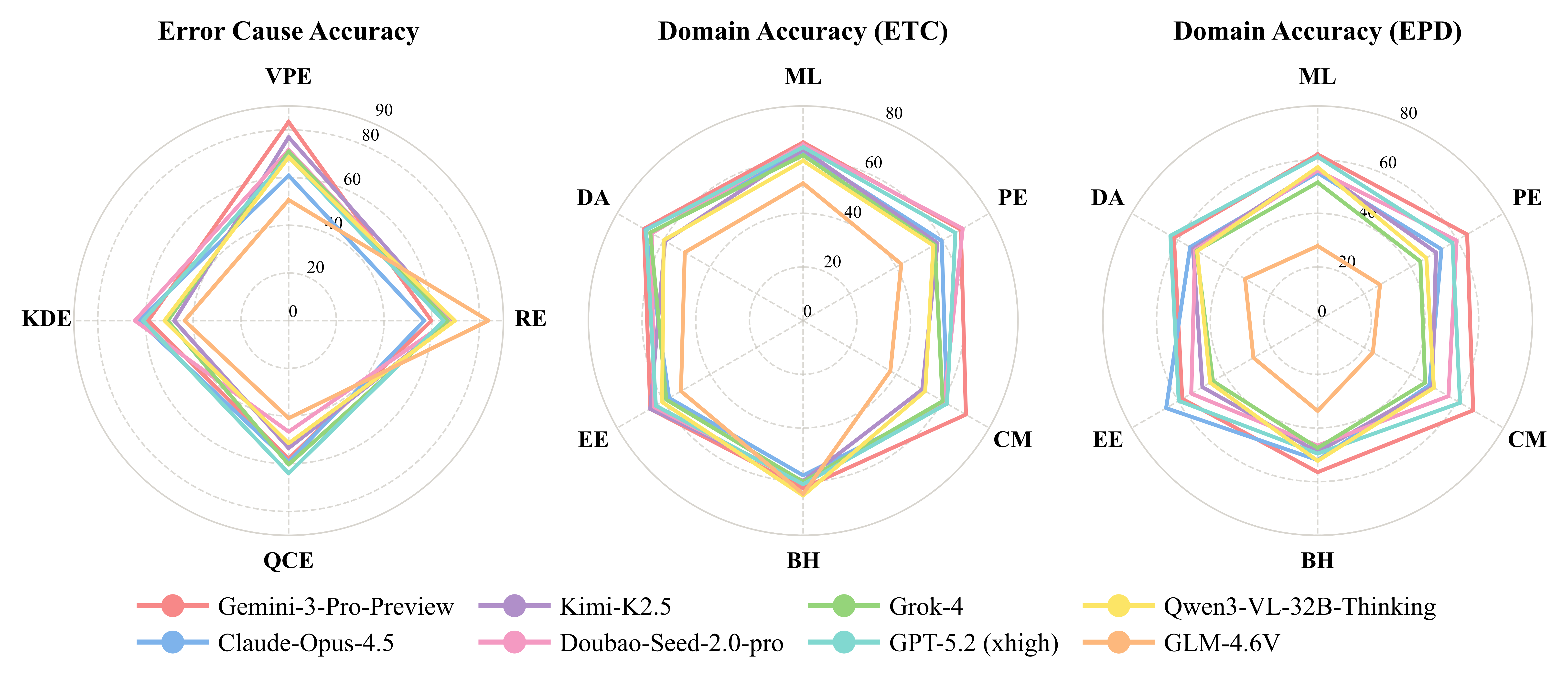

Error taxonomy spans visual perception, knowledge deployment, question comprehension, and reasoning failures.
1,997 multimodal cases across six domains and 24 subdomains—distribution and benchmark summary.

Two evaluation modes: Error Type Classification (ETC) and Error Presence Detection (EPD).

12 representative VLMs evaluated; Gemini-3-Pro-Preview reaches 66.65% error-type accuracy.
Benchmark Tasks
Error Type Classification (ETC)
The model is explicitly told an error exists and must classify it using the MMErroR taxonomy (visual perception, knowledge deployment, question comprehension, reasoning).
Error Presence Detection (EPD)
The model first decides whether a reasoning chain is sound, and only then diagnoses the error if present—mirroring real-world uncertainty.
MMErroR targets process-level understanding: VLMs must look beyond answer correctness to locate why reasoning fails.
MMErroR Taxonomy
Visual Perception Error
Incorrect grounding such as object misidentification, spatial misinterpretation, or misreading symbols/diagrams.
Knowledge Deployment Error
Misuse or misapplication of external knowledge—e.g., physics, math formulas, or domain-specific concepts.
Question Comprehension Error
Misunderstanding task intent, overlooking constraints, or misinterpreting the required target.
Reasoning Error
Logical fallacies, missing premises, invalid inference steps, or internal inconsistencies in the reasoning chain.
Figure 1: MMErroR Benchmark Overview
arXiv
BibTeX
@article{shi2026mmerror,
title={MMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models},
author={Shi, Yang and Xie, Yifeng and Guo, Minzhe and Lu, Liangsi and Huang, Mingxuan and Wang, Jingchao and Zhu, Zhihong and Xu, Boyan and Huang, Zhiqi},
journal={arXiv preprint arXiv:2601.03331},
year={2026}
}